
Introduction
📄![]() 2017-AAAIAI-Robust Loss Functions under Label Noise for Deep Neural Networks. では、MAEはNoise torelantであるとわかったが、これ自体を学習に使うのはDNNにおいて向いてない。
2017-AAAIAI-Robust Loss Functions under Label Noise for Deep Neural Networks. では、MAEはNoise torelantであるとわかったが、これ自体を学習に使うのはDNNにおいて向いてない。
そこで、MAEとCCEの両方を組み合わせることで、新たな損失関数GCEを開発してよい性能を得た。提案手法は以下の2つのNoisy Labelの問題設定で有効。
- Open Set 訓練データの一部のNoisy Labelの本来のクラスは、与えられたクラスに含まれていないものである。
- 例えば「犬」、「猫」、「猿」のクラスがあるのに、クジラの画像とか。
- Closed Set 訓練データの一部のNoisy Labelの本来のクラスは、与えられたクラスに含まれているものである。
- 「犬」を「猫」に間違えたような。
Related Works
📄![]() 2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
ノイズ混同行列の方法については、DNNが十分な容量を持ち、ノイズ混同行列は対角優位なら、元のCCEと同じように収束するらしい。
SVMでは、Ramp, Hinge, Savage() Lossがノイズに強いらしい。
あとはSmall Loss Trickを使ったり、真のラベルを潜在変数として扱い、EMアルゴリズムのように解くことができる。Cleanなデータセットのgradientと近いようなサンプルはCleanだと扱うやり方もある。
Generalized Cross Entropy Loss
問題設定
- サンプルはで、ラベルはとなる。
- データは個ある。
- 識別器はDNNであり、である。
- 目標は次の損失関数の最小化である。
📄![]() 2017-AAAIAI-Robust Loss Functions under Label Noise for Deep Neural Networks. によれば、MAEは対称的な損失で、次のように計算できるのでノイズに強い。
2017-AAAIAI-Robust Loss Functions under Label Noise for Deep Neural Networks. によれば、MAEは対称的な損失で、次のように計算できるのでノイズに強い。
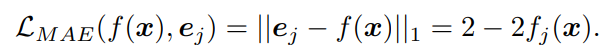
DNNではなぜMAEは悪いのか
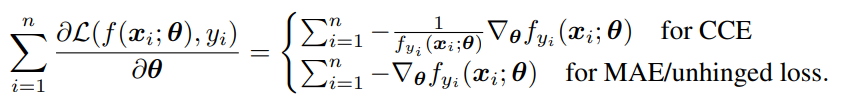
以上がCCEとMAEの勾配である。
CCEでは、は予測分布の正解ラベルにあたる値だが、これが小さいほどがっつり学習しないといけないということで大きな重みを与えているとわかる。
Cleanなラベルでは学習を加速させるだけだが、Noisyなデータについては間違ったまま過学習させてしまう。
MAEでは、スケーリングが存在しないのでノイズには強いが学習が非常に遅く、誤ったサンプルを重点的に学習させることもまた難しい。
この問題はデータセットが難しければ難しいほど顕著になる。
提案手法
MAEの性質を保ちつつ学習が遅い問題を解決するために、Box-Cox変換をする。。

この時、にしたときにロピタルの定理を使いつつ、マクローリン展開でを使うと、以下のようにCCEになるとわかる。
Box-Cox変換した形は、以下の式のように範囲が制約されている。
最大値は、であることから、q乗がついてもが分子で抑えられる。
最小値は、すべてのであるとき。
そしてこのBox-Cox変換された損失は、、先行研究のようにを満たすようなノイズがあるとき、真のラベルでの損失とNoisy Labelでの学習した損失の差は抑えられる。
がNoisy Labelでの学習結果。
- が1に近いほど、は0へと近づいてよい評価になる。
- の時はMAE損失である。
- になったらCCEである。
- うまくを操作することでいいとこどりの性能を得るのがGCE。
実際、GCEの勾配を見てみると、適切な重みをつけているように見える。
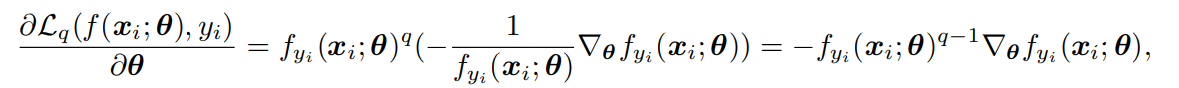
を切り詰める
をもとに新たな「切り詰めた」損失関数を定義する。
ある閾値以上の時はBox-Cox変換された損失関数を使うが、未満の時はの代わりにを使う、つまりとなり、本来よりも損失を小さくすることができる=学習するべき影響を抑えられる。これで、Denoise機能をさらに上げることができる。
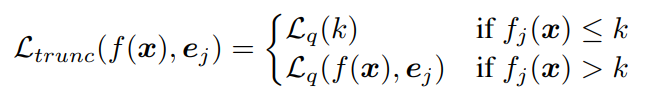
これをによってどっちを使うかを選択するように定式化させると以下のようになる。
本来は二値のみ取るが、これを二変数の凸最適化問題に帰着することができる。これは片方を固定してもう片方を最適化、というのを繰り返すことで最適化できる。
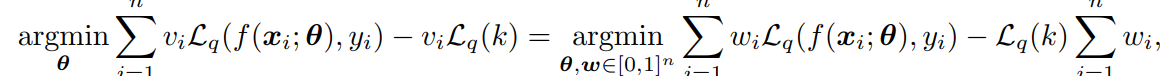
しかし、DNNは非凸関数であるものの、これと同じようにACSをしてもうまくいくことが多い。この作業をPruningという。
ACSを用いるときの最終的なアルゴリズム

すべてのパラメタにおいて、先ほどの言うようにACSを使って、相互にパラメタを更新する感じである。
もちろん、だけ使ってもよい。
Experiments
が高いと、過学習が遅れてより多くの特徴を学べる。ただ多ければ多いほどいいわけじゃない。
CIFAR10, CIFAR100, FMNISTで訓練していて、とした。